Usage
Once you have a Recode integrated and configured you’re ready to start using Recode. This guide takes you through the basics of Recoding.
Editing code at runtime
To edit code at runtime you need to start a debugging session, modify some code and then invoke Recode either via the Recode menu
or by using the Recode button in the Debug toolbar. You can also use the keyboard shortcut (the default is Shift+F10).

If you have edited files within Visual Studio, Recode will save them, analyze the solution, compile modified files, link them into a patch file and finally inject the patch into the debugged process. The Recode output window displays progress and any warnings or errors:
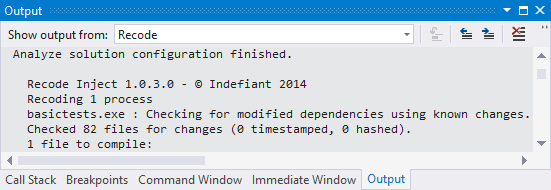
When Recode completes one of the following notification popup will briefly be overlaid on screen.


The tick indicates success and the cross indicates failure. In case of failure, check the Recode output window to diagnose the error.
What can I edit?
Recode supports most changes to existing code with few limitations. Structural changes to code, such as inserting or removing data members, may be done provided you understand the limitations outlined below.
Recode can reliably support the following types of changes at runtime:
Edit headers and source files alike.
Add/remove #include directives.
Add/remove global variables.
Add/remove/modify functions and non-virtual methods declarations and implementations.
Modify virtual function implementations.
Can I edit currently executing code?
Yes, you can successfully edit and Recode a function currently on the stack but you must be aware of this key restriction:
Important
If you edit a function currently on the stack, the new code will not execute until the function is reentered. Until then, the old code will continue to execute.
As most long-running game engine or application code is based around an update loop this is rarely an issue. But two cases can cause confusion:
1. Editing code in the current function while the debugger is paused.
int DoStuff()
{
DoFoo(); // 1. Pause the debugger here
int a = 42; // 2. Edit this value & Recode
return a; // 3. Set a breakpoint here & resume the debugger
}
If you were to pause the debugger in this function, and change 42 to something else, Recoding the change would
succeed, but the updated code will only be executed the next time DoStuff(int a) is reentered. While the old function
remains on the stack, continuing the debugger will continue to execute the old code and will return 42
rather than the updated value from the new code.
Additionally, a breakpoint set on the return statement will not stop the debugger from exiting the old version of the function. This is because the breakpoint is set on the new version of the code that is loaded into memory but isn’t yet being executed
Since the version of the file no longer matches the version the old code was built with, breakpoints can’t be set on the old code via the code view. If you need to be able to breakpoint old code that no longer matches the edited files, the best way is to pause the debugger with the old code on the stack and go to the disassembly view. In disassembly view you can set a breakpoint on the old code since it doesn’t require a one-to-one mapping with the updated source code.
2. Editing code in a function that is never reentered.
Some functions at the base of the stack will never be reentered for the lifetime of the program and therefore can’t
be updated using Recode. Common examples of such functions are process entry points such as main(),
WinMain() and thread startup functions.
Other functions that may not be reentered are ones that manage update or event loops, since they typically execute until the program exits. Since such functions always remain on the stack and aren’t recursive, any updates to them applied via Recode will never get executed.
For example this main() function cannot be updated by Recode as it will always remain on the stack until the program exits:
int main()
{
// The body of this function will never be reentered
while (!ExitRequested())
{
DoThings();
}
return 0;
}
The same issue applies to event loops as the function will typically remain on the stack for the lifetime of the UI process:
int RunMessageLoop()
{
// This function will stay on the stack until WM_QUIT is received
MSG msg;
BOOL bRet;
while ((bRet = GetMessage(&msg, NULL, 0, 0)) != 0)
{
if (bRet != -1)
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
}
return msg.wParam;
}
If you want to edit the code contained within a long-running loop using Recode, it’s best to move the code within the loop to its own function that will be reentered at each iteration of the loop. That way, while the original function cannot be updated via Recode, the code it executes can be updated via the new child function.
Structural Changes
Any code accessing a class or struct will expect the memory layout it saw at the time of compilation. Therefore if you do change the layout of a class or struct between Recode patches you have to consider if there will be old instances of the class or struct left in memory and whether the new code can safely handle the new layout.
Adding members at runtime
Adding members at runtime is possible, but you need to take care. The following example shows some of the pitfalls.
Here we start with a struct Foo:
struct Foo
{
int m_a; // Offset: 0 bytes
int m_c; // Offset: 4 bytes
}; // Sizeof: 8 bytes
int SumFoo(Foo& foo)
{
return foo.m_a + foo.m_c;
}
Then we decide to use Recode to add a new member to Foo called m_b and update SumFoo() accordingly:
struct Foo
{
int m_a; // Offset: 0 bytes
int m_b; // Offset: 4 bytes (was m_c)
int m_c; // Offset: 8 bytes (never allocated or initialized on old instances)
}; // Sizeof: 12 bytes
int SumFoo(Foo& foo)
{
return foo.m_a
+ foo.m_b // Gives the value for m_c for old instances
+ foo.m_c; // Gives undefined value or access violation for old instances
}
Now any old instances of Foo (created before the Recode) would now have their m_c member supplanted by the newly introduced m_b member. Meanwhile new code trying to access m_c on an old instance runs the risk of an access violation or at the very least an undefined value.
The safest approach for adding members like this is to provide a way to destroy and recreate the working set of instances you intend to restructure. Obviously this isn’t possible in all cases but for many games, reloading a level or reinitialising the owning system may suffice.
Removing members at runtime
Removing data members is possible at runtime but care must be taken if removing a member that is not at the end of a class or structure. If you do remove a middle member then the members following the removed member will be at the wrong offset for the new code as the following example demonstrates.
struct Bar
{
int m_a; // Offset: 0 bytes
int m_b; // Offset: 4 bytes
int m_c; // Offset: 8 bytes
}; // Sizeof: 12 bytes
int SumBar(Bar& bar)
{
return bar.m_a
+ bar.m_b
+ bar.m_c;
}
Now we remove m_b from Bar and Recode:
struct Bar
{
int m_a; // Offset: 0 bytes
int m_c; // Offset: 4 bytes
}; // Sizeof: 8 bytes
int SumBar(Bar& bar)
{
return bar.m_a
+ bar.m_c; // Gives value of m_b for old Bar instances
}
In this case there is no immediate risk to stability, simply an incorrect value for m_c if old instances are passed to SumBar(). However, if m_c were a pointer rather than a simple integer this could cause an access violation.
External Changes
If you modified files outside of Visual Studio, Recode will not detect them automatically since only edits
made inside Visual Studio are tracked. However, you can instead use Recode (Check All) to force Recode to check every source file
for changes. This is not done by default as it can be quite slow for large solutions.
If you attempt a standard Recode without editing any files with Visual Studio you will asked if you want to check all files for external changes:
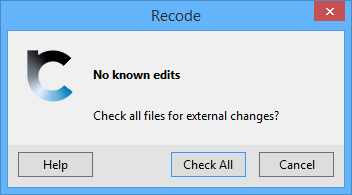
Check All will force Recode to check all the files for external modifications.